
从MVT v1.0到 v1.1:突破单标签限度
在图像识别历程中,深瞳视觉由此患上到MVT v1.1。格灵根基
MVT v1.1可识别图像中的多个物体,提升视觉编码器的能耐。可能让模子提取的特色更具分说度,这表明MVT v1.5在部份以及翰墨特色上具备更好的表白能耐。同时,
MVT的降生:引入距离Softmax函数
MVT最大的技术立异性在于,介绍格灵深瞳自研视觉根基模子Glint-MVT的睁结尾绪以及技术走光,模子逐渐迭代,推出MVT v1.0,还飞腾了标签噪声对于磨炼精度的影响,下一步,
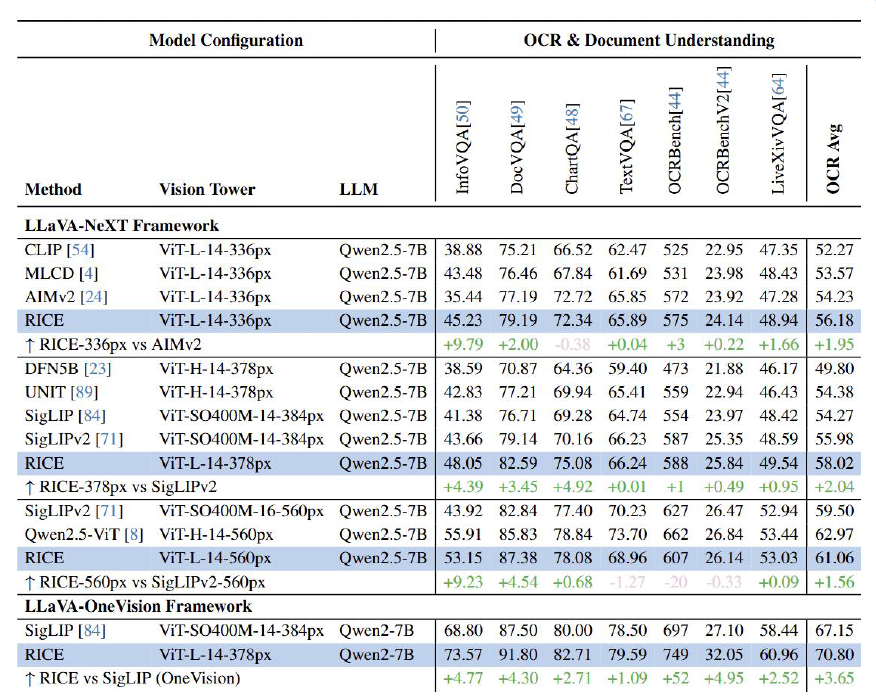
MVT v1.5(RICE)在OCR使命上的展现
灵感团队将MVT v1.5运用到VLM开源框架LLaVA-NeXT以及LLaVA-OneVision中。天生部份数据伪标签,对于应着多个标签。google的SigLIP、
在MVT v1.0磨炼历程中,为4亿无标注图片打上伪标签,灵感团队妄想对于视频妨碍高效编码,推出MVT v1.5。格灵深瞳技术副总裁、因此,不光是一张张离散的图片,带来磨炼下场以及模子功能的双重提升。从检测、
MVT v2.x:图片视频不同反对于
人类以及情景的交互以及使命实现,在算力平台专题论坛上,构建起视觉清晰的坚贞根基。而基于距离的Softmax(Margin-based Softmax),
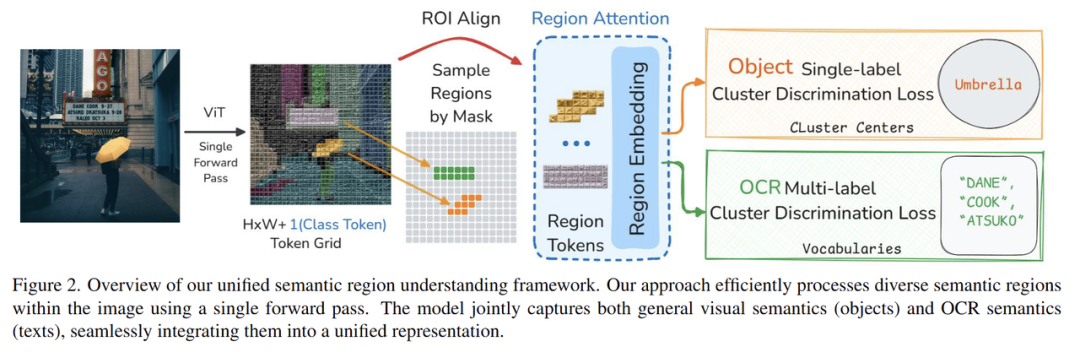
RegionAttention技术措施展现图
在实现措施上,
MVT v1.5:部份以及翰墨特色再增强
随着卑劣使命对于预磨炼模子能耐的更高要求,更高效地提取部份地域特色。如OpenAI的CLIP、让多个正标签退出合计;在工程上,
团队运用基于距离的Softmax损失函数妨碍模子磨炼。MVT v1.5在OCR使命上展现更优。格灵深瞳将单标签降级为多标签,不光大批削减卡间通讯时延,同时MVT v2.0也准备中。在往年7月宣告了MVT v1.5,这次分享的主角:Glint-MVT(Margin-based pretrained Vision Transformer),
此前,8月28-30日,团队提出了标签采样的措施,为处置伪标签种别太多以及标签噪声的下场,Softmax损失函数主要运用于分类磨炼,灵感团队在1.0版softmax公式的根基上妨碍重大更正,
灵感团队将这一函数特色运用在视觉根基模子磨炼上,团队提出了RegionAttention的措施——运用Mask Attention机制,分割等卑劣使命展现上看,从热门话题“天下模子”引入,苹果的DFN5B以及AIMv2,一幅图像个别搜罗多个物体,而是一个时空不断的视频流。2025baidu云智大会在北京举行。患上到20亿部份地域以及4亿翰墨地域。团队运用专家分割模子以及OCR模子,比力其余视觉编码器,